
설계와 아키텍처란?
- 설계 : 저수준의 구조 또는 결정사항 등을 의미
- 아키텍처 : 저수준의 세부사항과는 분리된 고수준의 무언가
이 부분은 애매했다. 무언가 설계와 아키텍처를 분리하면서도 책에서는 둘의 경계는 무관하다고 했다. 하지만 내 안의 의문은 계속해서 이 둘의 차이가 마음에 걸렸다.
What’s the difference between software architecture and design?
Building software is a complicated process made up of many different parts. Among them are developing software architecture and design…
medium.com
위의 글에서 어느정도 내가 고민하던 - 혹은 의문을 품었던 - 부분을 해결해 주었다. 정리하자면 다음과 같다.
- 소프트웨어 설계
- 소프트웨어 설계는 시스템을 구성하는 서로다른 요소들에 탐구하는 계획이다.
- 설계 플랜은 개발 프로세스를 통해 가치있는 참고 자료로 여겨질 수 있다.
- 설계 플랜은 "요구사항 분석", "위험 분석" 그리고 "도메인 분석"을 필요로한다.
- 소프트웨어 설계는 요구사항을 실체로 바꾸는 개발자들을 도와준다.
- 소프트웨어 아키텍처
- 소프트웨어 시스템의 청사진. 각각의 컴포넌트들이 소통 및 협력하도록 설정하고 시스템의 복잡도를 다룰 수 있게 해준다.
- 소프트웨어 아키텍처는 비즈니스와 기술적 요소들이 만나는 지점, 구조화된 해결책이다.
- 이러한 아키텍처의 목표는 어플리케이션의 구조에 영향을 미치는 요구사항을 명확하게 하는 것에 있다.
- 차이와 관계
- 아키텍처는 시스템의 구조를 보여주면서 세부 구현을 숨겨주며, 시스템 구성 요소가 다른 요소와 상호작용하도록 도와준다.
- 설계는 반대로 시스템의 실행에 집중하며, 고려가능한 세부사항을 탐구하기도 한다.
- 개발 팀은 가끔씩 소프트웨어 개발보다 설계에 혹은 그 반대에 집중하기도 한다.
- 결국 이 둘 사이에 선을 긋는 것은 개발자의 몫이다.
결국 이 둘 사의 관계는 상호 보완적이지만, 이 둘 사이의 적절한 템포 혹은 선을 긋는 것도 필요하다는 내용이다. 내게 있어서는 설계들이 모여 하나의 컴포넌트를 이루고 그 컴포넌트(구성 요소)들이 모여 하나의 아키텍처를 구성하는 것처럼 느껴졌다.
프로그래밍 패러다임
이 책에서는 구조적 프로그래밍, 객체 지향 프로그래밍, 그리고 함수형 프로그래밍을 차례차례로 소개한다. 나는 그 전에 가장 인상적인 구문이 있어서 소개하려 한다.
패러다임은 프로그래머에게 새로운 권한을 주는게 아니라 하면 안될것을 정의하고 할 수 있는것을 박탈한다.
즉 무엇을 해야 할지를 말하기 보다는 무엇을 해서는 안되는 지를 말해준다.
간단하게 각 패러다임을 소개하자면.
- 구조적 프로그래밍 : 최초로 적용된 프로그래밍, 다익스트라가 발견, goto문의 해로움에 대해 논함. 제어 흐름의 직접적인 전환에 대해 규칙을 부과.
- 객체지향 프로그래밍 : ALGOL의 함수 호출 스택 프레임을 힙으로 옮기면 지역변수가 오랫동안 유지되는 것에서 시작. 제어 흐름의 간접적인 전환에 대해 규칙을 부과
- 함수형 프로그래밍 : 불변성, 할당문에 대해 규칙을 부과
사실 이 말이 왜 나왔을까 고민하다가, 예전에 봤던 C언어의 유명한 구문이 생각났다. 정확히는 C99 Rationale에 나온 말이다.

C의 정신을 지키라. C89 위원회는 C의 전통적인 정신을 보존하는 것을 주요 목표로 삼았습니다. C의 정신에는 많은 측면이 있지만, 그 본질은 C 언어가 기반하고 있는 15가지 근본 원칙에 대한 커뮤니티의 정서입니다. C의 정신의 일부 측면들은 "간결함", "이식성", "효율성" 등의 문구로 요약될 수 있습니다.
- 프로그래머를 신뢰하라.
- 프로그래머가 필요한 일을 하는 것을 막지 말라.
- 언어를 작고 단순하게 유지하라.
- 실행에는 한가지 방법만 제공하라.
- 이식성이 보장되지 않더라도 빠른 실행 속도를 지향하라.
나는 위의 첫번째 말이 제일 현 세대의 다양한 패러다임의 탄생에 기여를 했다고 생각한다. 즉 "프로그래머를 신뢰"하지 못해서 하나씩 권한을 빼앗은 것이 아닐까 하는 생각이 들었다. 이는 사실 패러다임뿐 만이 아니라 언어에도 영향을 주었다고 본다.
결국 Python, JAVA, JavaScript, GO, Rust 등등의 탄생은 프로그래머를 신뢰하지 못해 - 사실 신뢰하지 못하기 보다는 휴먼 에러의 방지에 가까울 것 같다 - 일어난 현상이 아닐까 조심스레 추측해 본다. 결국은 더 안전한 프로덕트를 만들기 위한 방향으로 진화한 것이 아닐까?
객체 지향 프로그래밍(OOP, Object Oriented Programming)
캡슐화와 추상화
자동차를 생각해보자, 자동차가 달려가고 있다. 그 안에는 수많은 움직이는 부품들이 있고, 작게는 기어부터 시작해 톱니바퀴까지 움직인다. 우리는 이 자동차 내에 수많은 움직임이 다른 움직임을 만들어 내고, 상호작용하고 있다는 것을 알 수 있다. 그와 동시에, 차체를 보자, 차체는 크게보면 디자인이 있지만, 그 안에는 다양한 프레임과 함께 견골들이 존재한다. 우리는 자동차에 엔진이 있다는 것을 알고 배터리부터 다양한 부품이 있다는 것을 안다.
단순하게 말해서, 캡슐화는 "어떠한 정보 혹은 데이터의 은닉"이다. 추상화는 "어떠한 실행 혹은 행동의 은닉"이다.
상속
class Country:
name = '국가명'
population = '인구'
capital = '수도'
def show(self):
print('국가 클래스의 메소드입니다.')
class Korea(Country):
def __init__(self, name):
self.name = name
def show_name(self):
print('국가 이름은 : ', self.name)
상속은 책에서 너무 효과적으로 설명했다. "어떤 변수와 함수를 하나의 유효 범위로 묶어 재정의"
다형성 및 의존성 역전 원칙
class BaseUserRepository(ABC):
def get_user_all(self, db: Session) -> List[User]:
pass
class UserRepository(BaseUserRepository):
async def get_user_all(self, db: Session) -> Optional[List[User]]:
query = await db.execute(select(UserModel))
result = query.scalars().all()
if result:
return result
return None
다형성은 결국 다양한 형태, 즉 하나의 객체가 다른 여러 가지 타입을 가질 수 있음을 의미한다. 왜 이런 다형성이 필요한 것일까? 결국 개발의 용이함, 유지 보수의 기회비용을 줄이기 위함이 아닐까 생각한다. 기존 코드 자체에 이미 고수준 - 위의 코드에서는 BaseUserRepository - 객체로 동작에 초점을 맞춰 구현했기 때문에, 저수준 - 위의 코드에서는 BaseUserRepository를 상속하는 UserRepository - 객체를 변경해주면 원래 코드 수정 없이 변경이 가능하다.
그리고 이러한 다형성 원칙은 곧 의존성 역전 원칙으로 이어진다. 의존성 역전을 위해 추상화(인터페이스)를 개발하고 외부 코드가 인터페이스에 의존적이도록 해야한다.
함수형 프로그래밍(FP, Functional Programming)
불변성과 아키텍처
- 경쟁 조건, 교착, 동시성 문제는 가변 변수로 인해 발생
- 하지만 모든 변수를 불변으로 유지 불가능, 여기서 가변성의 분리가 등장
- 내부 서비스를 가변 컴포넌트와 불변 컴포넌트로 분리
- 불변 컴포넌트는 변수의 상태를 변경할 수 있는 다른 컴포넌트와 통신
- 가변 컴포넌트는 최소한으로 해야 한다.
- 저장 공간과 처리 능력만 충분하면 완전히 불변성을 만들 수 있다. 그리고 완전한 함수형이 가능
- 저장과 처리공간에 대한 제약이 사라지면서, 실제 데이터를 변경하는 것이 아닌, 검색 및 삽입만 하는 방식이 등장
- 이벤트 소싱은 상태가 아닌 트랜잭션을 저장하여 상태가 필요해지는 순간 초기 상태에서 모든 실행된 트랜잭션을 추적하여 현재 값을 파악
트랜잭션이란?
- 트랜잭션이란, 데이터베이스에서 이루어지는 연속되는 여러 실행 단위를 묶어둔 것이라고 생각하면 된다. 그리고 각각은 하나의 논리적인 작업의 유닛으로 제공된다. 예를들어 설명해보겠다. A라는 유저가 B라는 유저에게 500만원을 보낸다고 해보자. 그러면 다음과 같은 실행이 일어난다.
- (데이터베이스 트랜잭션의 시작이라고 불리는) 유저 A에게서 B에게 500만원을 보낸다는 기록을 만든다.
- 유저 A에게서 잔고를 확인한다.
- 유저 A의 잔고에서 500만원을 뺀다.
- 유저 B의 잔고를 읽는다.
- 유저 B의 잔고에다가 500만원을 추가한다.
만약 이러한 트랜잭션을 하나의 원자성(하나의 깨지지 않는) 유닛으로 처리하고 만약 시스템이 이러한 트랜잭션을 도중에 실패하면, 트랜잭션은 완료되지 않은 상태에서 기존의 상태로 돌아간다. 일반적으로 롤백(rollback)이라는 단어는 트랜잭션을 통해 만들어진 어느 변화든 미완료 상태에 놓인 프로세스를 되돌리는 것을 말한다. 커밋(commit)이라는 단어는 트랜잭션을 통해 영구적인 변화가 이루어진 경우를 언급한다.
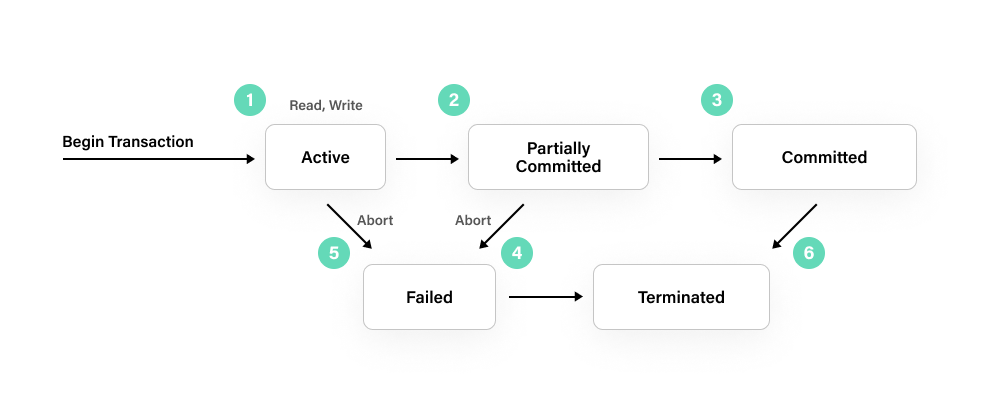
- 활성 상태(Active) - 트랜잭션의 첫번째 상태이다. 트랜잭션의 명령어(읽고 쓰는 작업)이 실행되는 동안 활성되어 있다.
- 일부 커밋된 상태(Partially Commited) - 이 상태로 변한 경우 데이터베이스는 아직 디스크에 데이터를 커밋하지 않은 상태이다. 이러한 상태의 경우 메모리 버퍼에 있는 경우이며, 이 버퍼에 있는 데이터가 아직 쓰이지 않은 경우이다.
- 커밋된 상태(Committed) - 이 상태의 경우 데이터베이스에 영구적으로 저장된 상태이다. 그렇기에, 이 상태 이전으로 롤백은 불가능하다.
- 실패(Failed) - 만약 일부 커밋된 상태라든지, 활성 상태에서 트랜잭션이 거부되거나 실패한 경우 실패 상태에 진입한다.
- 종료(Terminated) - 마지막 상태로 데이터베이스 트랜잭션의 라이프 사이클의 최종 단계이다.




