
기본적인 모델 구조 예시
from django.db import models
class Customer(models.Model):
user = models.OneToOneField(User, null=True, blank=True, on_delete=models.CASCADE)
phone = models.CharField(max_length=20, null=True)
address = models.CharField(max_length=100, null=True)
city = models.CharField(max_length=50, null=True)
state = models.CharField(max_length=50, null=True)
zipcode = models.CharField(max_length=10, null=True)
country = models.CharField(max_length=50, null=True)
class Meta:
app_label = "shopping"
class Order(models.Model):
customer = models.ForeignKey(Customer, null=True, on_delete=models.SET_NULL)
products = models.ManyToManyField(Product, related_name="orders")
order_created = models.DateTimeField(auto_now_add=True)
class Meta:
app_label = "shopping"
class Product(models.Model):
name = models.CharField(max_length=100, null=True)
price = models.FloatField(null=True)
class Meta:
app_label = "shopping"
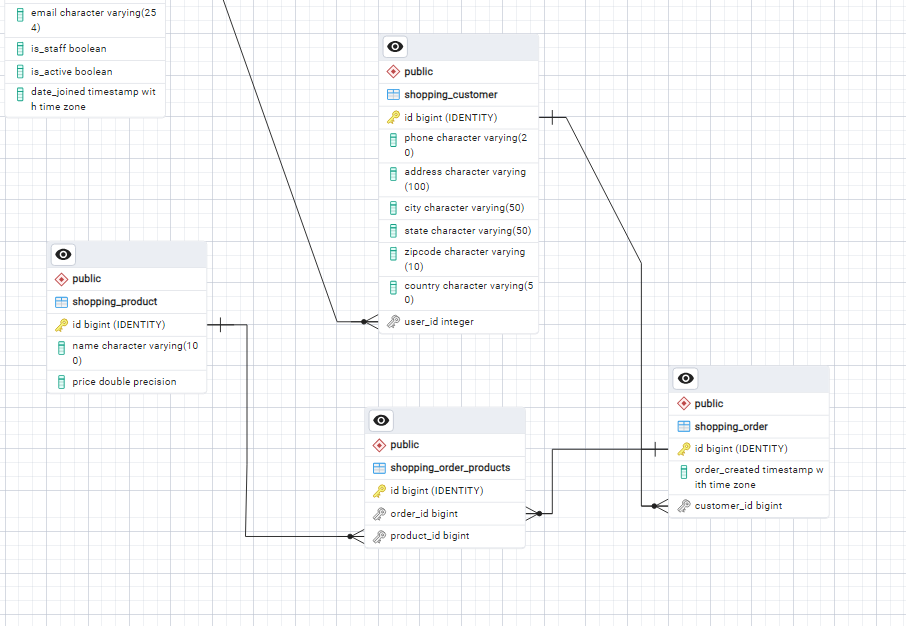
위와 같은 코드가 있다고 하자. 위의 코드는 Django의 Model로 쇼핑에서 고객, 제품 그리고 주문을 각기 표시한 것이다. 이를 ERD로 표시하면 다음과 같이 된다. 먼저 User와 Customer는 1:1관계이다. 그리고 Order에는 ForeignKey로 Customer를 참조한다. 즉 1:N관계이며 Customer <- Order의 관계가 된다. 그리고 Order에서 ManyToMany모델을 사용해서 Order와 Product는 M:N관계이다.
이러한 모델에서 ORM을 사용할 경우 N+1 문제가 쉽게 발생할 수 있다. 이는 Django를 비롯한 ORM들의 Lazy Loading에서 비롯되는 문제이다.
QuerySet에 대해서 언급하자면, QuerySet은 전달받은 모델의 객체 목록이다. DB로부터 데이터를 읽고 필터를 걸거나 정렬 등을 할 수 있다. 리스트와 구조는 같지만 파이썬 기본 자료구조가 아니기에 사용을 위해서는 변환을 해줘야한다.
Lazy Loading vs Eager Loading
Lazy Loading이란 ORM이 DB에 요청을 하여 데이터를 가져올 때 ORM을 실행할 때 마다 가져오는 것이 아닌, 실제 데이터를 불러와야할 때 SQL등의 Query문을 날려서 가져오는 것이다. 즉, ORM을 실행할 때 보다 늦게 로딩이 된다고 이해하면 편할 것이다. 하지만, 실제로 어떻게 되는지는 잘 모른다. 밑의 그림을 보면 이해가 편할 것이다.
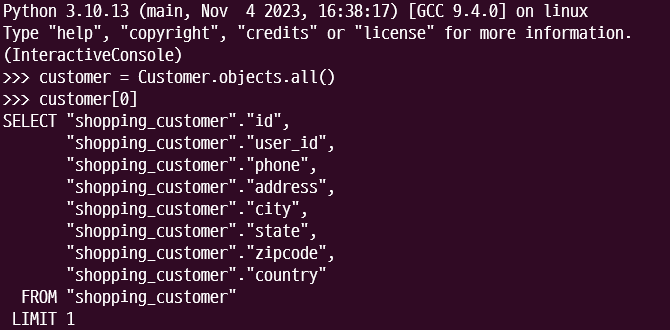
위의 그림에서 django-extensions의 --print-sql을 사용하여 실제로 쿼리를 날릴 때를 보여준다. 보면 Customer.objects.all()을 했을 때에는 아무것도 가져오지 않는다. 하지만 customer[0]을 해서 실제로 데이터를 조회하려고 할 때 쿼리문을 날리는 것을 알 수 있다. 이는 Django의 QuerySet이 평가되는 과정 중 하나이며, Django Docs에서는 QuerySet이 실제로 Database에 쿼리를 바로 보내는 것이 아닌 몇가지 평가될 때의 조건 하에서 보낸다고 한다. - 좀 더 간단히 말하면 QuerySet이 실행되어 실제로 Query문을 보내는 조건일 듯 하다.
Django
The web framework for perfectionists with deadlines.
docs.djangoproject.com
여기에는 다양한 조건이 있는데 다음과 같다.
- 순회(Iteration)할 때
customer = Customer.objects.all()
for cus in customer:
print(cust.id)- 슬라이싱(Slicing)할 때
customer = Customer.objects.all()
customer[0]- Pickling과 Caching
- repr(), len(), list()를 호출할 때
- bool()처럼 if문 등으로 쿼리셋의 진위여부 파악할 때
N+1 문제란?
customer = Customer.objects.all()
for cus in customer:
print(cus.user.id)
위와 같은 코드가 있다고 다시 생각해보자.
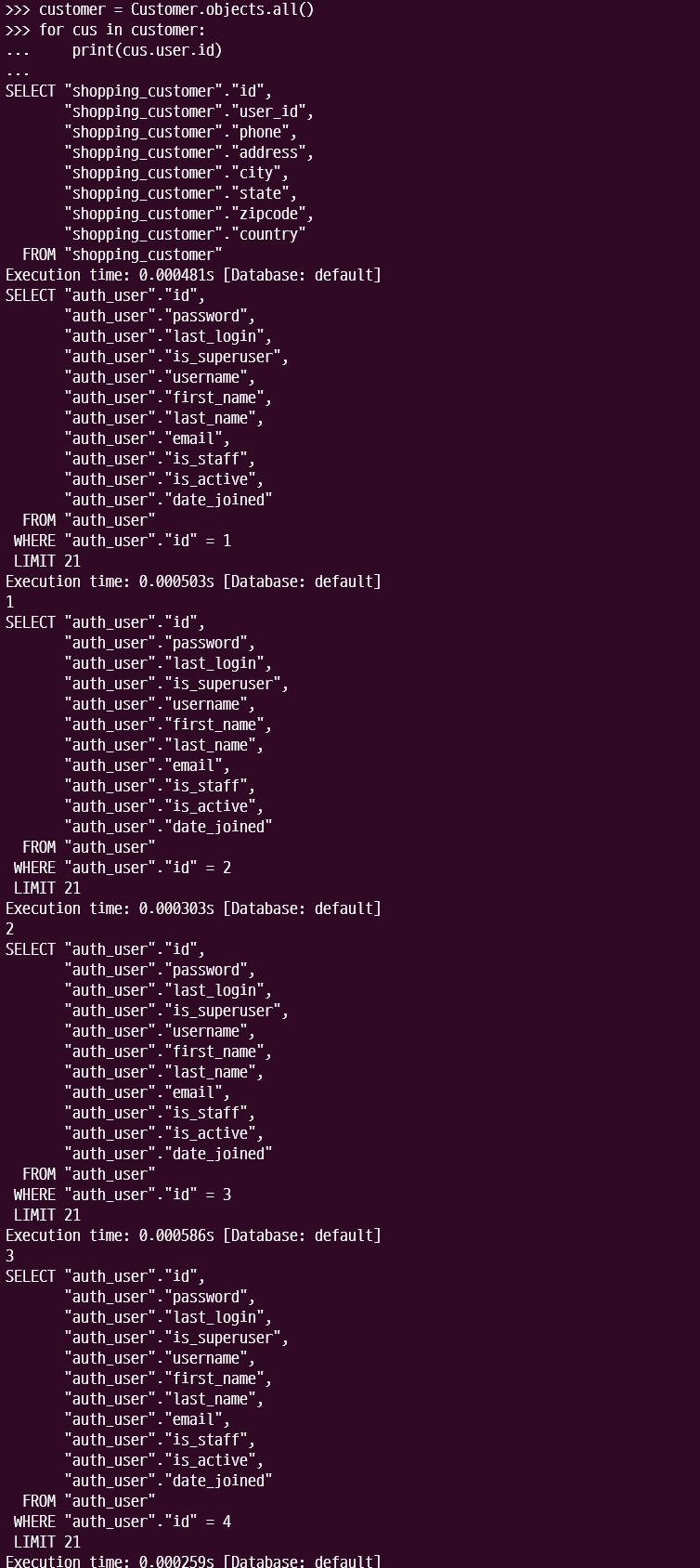
위의 실제 쿼리처럼, customer = Customer.objects.all()을 한 뒤 customer를 순회하면서 1:1관계에 있는 customer.user.id를 가져오려고 하면, Customer의 모든 정보는 SQL문을 한 번만 날리면 되지만 다시 user의 수만큼 query문을 날려야 한다. 즉 1+N에서 N이 추가적으로 발생한다는 점이다. 이럴 때 사용하는 것이 바로 select_related()이다.
select_related()는 JOIN을 통해 한번에 데이터를 가져오는 Eger Loading(즉시 로딩)방식이다. 즉, 기존에 쿼리문을 여러번 날리던 것을 한번에 뭉쳐서 날리는 것이다. 보통 1:1관계나, ForiegnKey를 가지고 있는 쪽에서 참조하는 1:N관계에서 사용된다.
customer = Customer.objects.select_related("user")
for cus in customer:
print(cus.user.id)

위의 코드를 개선하면 단 한번의 Query문을 날리는 것을 확인할 수 있다.
그렇다면 다른 관계인 ManyToMany같은 곳에서는 어떻게 사용할까, 일단 ManyToMany의 관계인 Product와 Order를 쿼리해보겠다.
products = Product.objects.all()
for product in products:
print(product.orders.all())
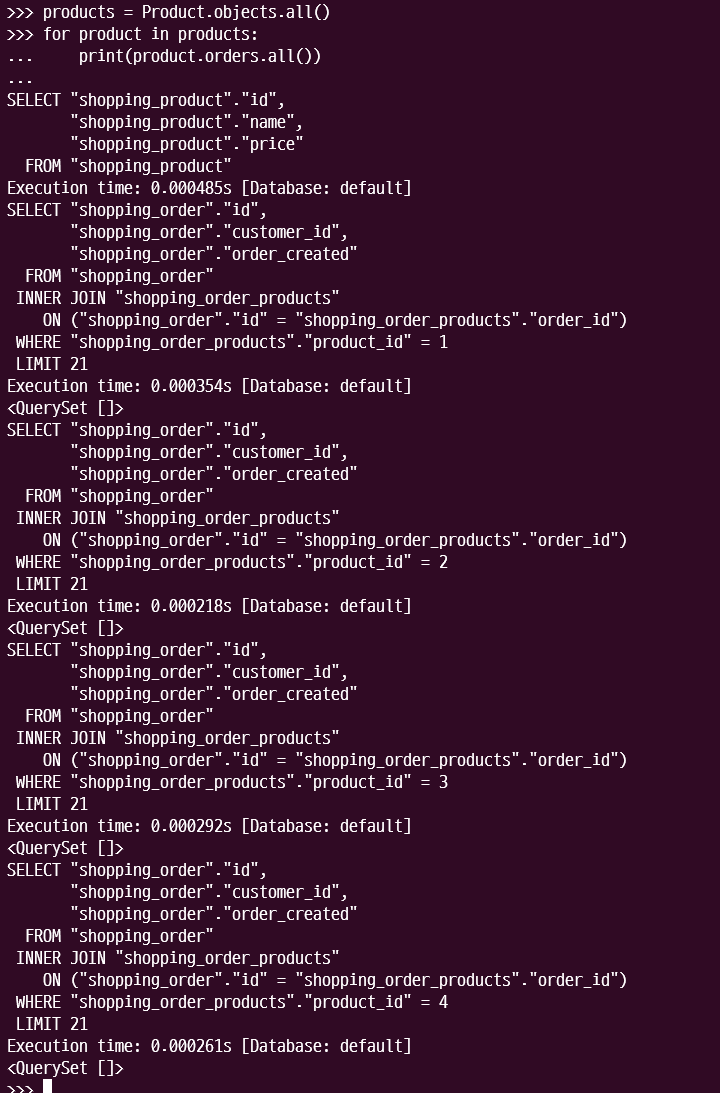
위의 Query문을 잘 살펴보면 처음에 Product를 찾고 각기 Product에 대해 Inner Join을 하는 것을 알 수 있다. 즉 1+N에서 N번의 쿼리가 더 발생한다. 이를 prefetch_related로 개선해 보겠다.
products = Product.objects.all().prefetch_related("orders")
for product in products:
print(product.orders.all())

보면, 단 두번의 쿼리로 질의를 끝내는 것을 알 수 있다. 여기서 알아야할 것은 select_related가 Inner Join으로 한번에 끝낸다면, prefetch_related는 메인 Query에서 이미 모든 관계가 있는 모델의 QuerySet Instance를 만들어낸다. 그래서 두번째 실행문인 product.orders.all()을 할 때 이미 관계가 cache에 저장해둔 상태이기에, product의 수만큼 order가 수행되더라도 db에 접근하지 않고 cache에서 찾아쓰게 된다.
'Python > Django' 카테고리의 다른 글
| [Django] QuerySet, Manager, Active Record 패턴, django-model-utils의 InheritanceManager들 톺아보기 및 성능 개선기 (2) | 2024.10.20 |
|---|---|
| [번역] Django REST Framework(장고 레스트 프레임워크): 장점과 단점 그리고 이의 대체제 (0) | 2024.05.11 |
| Django 모델 알아보기 - User 모델 및 커스터마이징 (0) | 2023.01.26 |
| Django 준비 - WSL2에 Django 설치하기, MVC, MVT알아보기 (0) | 2022.12.28 |




